Enterprise AI Engineering Platform — Local-first Memory + Governance
Model-agnostic workflows with inspectable memory. Use your own LLM subscriptions and keep data on your machine.
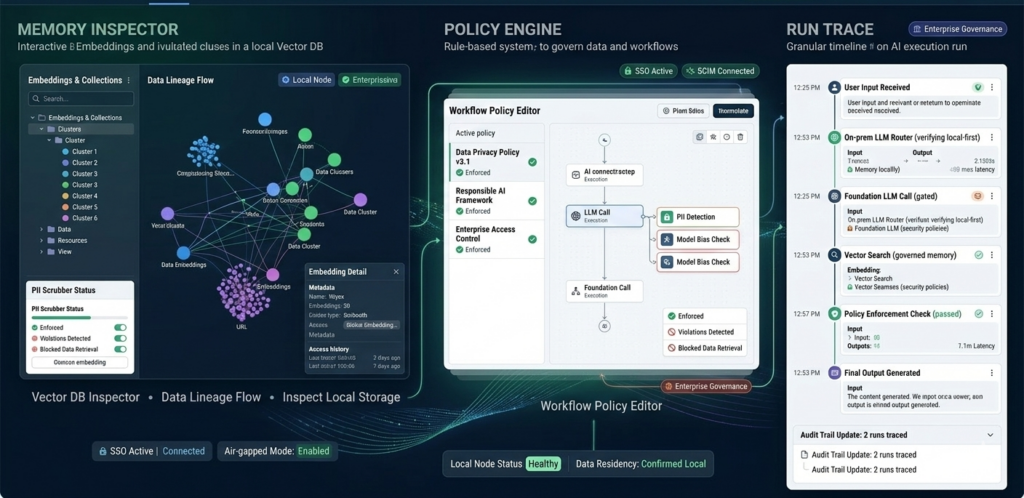
Nyex is a local-first AI orchestration and governance platform that lets teams safely operate multiple LLMs with shared memory, auditability, and enterprise controls — without owning model compute.
MCP Studio Adapter, HTTP Transport Inbound & Outbound
RBAC - Role based access control (Advanced)
SSO
Policy As Code (Advanced Governance)
Governance & Audit Logs (Full + Evidence)
Certified Build
Security Framework
Email Support (Priority + 24/7)
Hypercare Enterprise Support SLA (Contractual SLA)
Dedicated Success Engineer
Contact
+
Enterprise Inquiry
Quick contact
Sales email
Security email (security@)
Support portal link
Schedule a call
[ FAQs ]
AI Questions
& Answers
Explore common questions to better understand how our AI services work, their benefits, and how they can be tailored to your business needs.
Does any of our data get sent to your servers?
No.The platform is local-first. Your vector database, persistent memory, and workflow data are stored on your own machine or internal infrastructure.
If you connect to a foundation LLM (like OpenAI, Anthropic, Azure, etc.), data is only sent to that provider — under your own subscription and policies — not through us.
We do not host, store, or process your engineering data in the cloud.
How does token cost reduction actually work?
The platform routes tasks intelligently:
● Routine or structured tasks run on a local on-prem LLM.
● Higher-quality foundation models are used only when necessary.
● Persistent vector memory ensures only relevant context is retrieved, reducing unnecessary token load.
You use your own LLM subscriptions, so you only pay for what you consume — and the system minimizes unnecessary external calls.
What does “persistent memory” mean in practice?
Most AI tools forget everything between sessions.
Our platform stores structured memory in a local vector database so that:
● Knowledge persists across runs
● Context improves over time
● Memory entries can be inspected, edited, approved, or deprecated
● Workflows become stable and repeatable
This turns AI from “chat sessions” into a governed engineering system.
Is this tied to a specific LLM provider?
No. The platform is model-agnostic.
You can:
● Use OpenAI, Anthropic, Azure, or other foundation models
● Use a small on-prem LLM for local processing
● Switch providers without rebuilding your workflows
This prevents vendor lock-in and keeps your architecture flexible.
Is this suitable for enterprise or regulated environments?
Yes.
Because data and memory are stored locally, the platform supports:
● Stronger data control
● Reduced cloud exposure risk
● Air-gapped deployment options
● Policy enforcement and audit tracing
● SSO and role-based access control (Enterprise tier)
This significantly simplifies enterprise security reviews.
Do we need a large engineering team to use this?
No.
The platform is designed to reduce manual orchestration and repetitive AI setup.
It includes:
● Reusable workflows
● Built-in evaluation and replay
● Automated routing between models
● Governance and audit logging
Small teams can deliver production-grade AI systems without building complex infrastructure from scratch.
What kind of hardware is required to run the local LLM?
Requirements depend on the model size you choose.
For small on-prem LLMs used for routine processing, a modern machine with sufficient RAM is typically adequate.
Foundation models still run through your existing cloud subscription when higher-quality output is required.
You can scale your local model capacity based on your needs.
How is this different from using prompts in ChatGPT or other AI tools?
Chat-based tools are great for experiments.
This platform is built for engineering systems:
● Persistent memory
● Inspectable vector storage
● Replayable executions
● Governance and policy controls
● Multi-step workflow orchestration
● Enterprise auditability
It moves AI from experimentation to structured, repeatable, and governed production workflows.
How Does Licensing Work If Everything Runs Locally?
Even though the platform runs on your local machine or internal infrastructure, licensing still applies — because the license governs access to platform capabilities, not data hosting. There are two completely separate licenses involved:
a. License / Subscription for NYEX (The Platform)
This license gives you the right to use the NYEX AI Engineering Platform itself. What the NYEX license controls:
● Access to the platform software
● Feature tiers (Free / Pro / Team / Enterprise)
● Governance capabilities (policy engine, approvals, audit exports)
● Collaboration features (multi-user workspaces)
● Enterprise controls (SSO, RBAC, compliance modules)
● Certified builds and enterprise distribution (if applicable)
● Software updates and support What the NYEX license does NOT include:
● LLM token usage
● Foundation model subscription
● Cloud AI costs
● Local hardware costs
● The NYEX license governs the engineering infrastructure layer, not the AI compute layer.
b. License / Subscription for the LLM Provider
This is completely separate.
You bring your own:
● OpenAI subscription
● Anthropic subscription
● Azure OpenAI subscription
● Or any other foundation model provider
You pay those providers directly for:
● Token usage
● Model access
● API calls
● Any cloud compute involved
NYEX does not resell tokens and does not add markup to your LLM costs.
This means:
● You pay only for what you consume.
● You maintain full control over your LLM billing.
● You can switch providers without changing your NYEX license.
c. Local LLM Usage
If you use a small on-prem LLM:
You do not pay per token.
Costs are limited to your own hardware.
NYEX simply orchestrates and routes tasks to it.
NYEX provides the orchestration and governance layer — not the model license.
Why This Separation Matters 1. Cost Transparency
You see exactly what you’re paying for:
● Platform capability (NYEX)
● AI compute usage (LLM provider)
2. No Vendor Lock-in
You can:
● Change model providers
● Adjust usage patterns
● Control token consumption
Without affecting your NYEX license.
3. Enterprise Procurement Simplicity
Enterprises often:
● Already have LLM provider agreements
● Already have cloud contracts
● Already have model governance policies
NYEX integrates into those existing agreements rather than replacing them.
[ USE CASES & ROI ]
Shaping the Future of Your Business with
Smart AI Strategies
Document Control Use Case ID: `UC-002` Use Case Title: `Intermittent DNS/TLS Incident Diagnosis Across Client Networks` Version: `v1.0` Status: `Approved`…
Document Control Use Case ID: `UC-002` Use Case Title: `Intermittent DNS/TLS Incident Diagnosis Across Client Networks` Version: `v1.0` Status: `Approved`…